Sombra aquí, sombra allá: reconocimiento facial discriminatorio
Mientras que IBM ha cesado por completo el desarrollo de reconocimiento facial, Amazon y Microsoft lo han vendido a la policía

Mark Schiefelbein | AP
Con los avances en inteligencia artificial los sistemas de reconocimiento facial han proliferado. Se han desarrollado muchos servicios para identificar a personas en las multitudes, analizar sus emociones y detectar su género, edad, raza y características faciales. Ya se utilizan con una gran variedad de propósitos: desde contratar o mejorar sistemas de marketing hasta aspectos relacionados con seguridad y vigilancia.
Sin embargo, a pesar de los amplios esfuerzos para mejorar su fiabilidad, los estudios demuestran que los algoritmos de aprendizaje automático pueden discriminar según el género y la raza. También bajan su rendimiento en personas trans y no son capaces de clasificar a personas no binarias. Además, elementos como el maquillaje tienen un alto impacto en la precisión de los sistemas.
Los algoritmos de aprendizaje automático (Machine Learning) establecen patrones tras procesar grandes cantidades de datos. Son como estudiantes en un colegio: aprenden del libro de texto (información con la que se les entrena para que generen reglas de inferencia) y del profesorado (quien decide qué temas entrarán en el examen y les dice a sus estudiantes qué parámetros son importantes). Su limitación es que se pueden cargar de sesgos en varios puntos y de varias maneras.
La primera casuística se da cuando la realidad de la que aprenden está ya llena de prejuicios. La segunda, cuando les enseñamos solo una parte que no es representativa, que hace que los algoritmos piensen que esa es la única realidad. Otro punto de perversión se puede introducir durante la etapa de preparación de datos y la selección de modelos, cuando se hacen las preguntas equivocadas o se toman en consideración los parámetros erróneos.
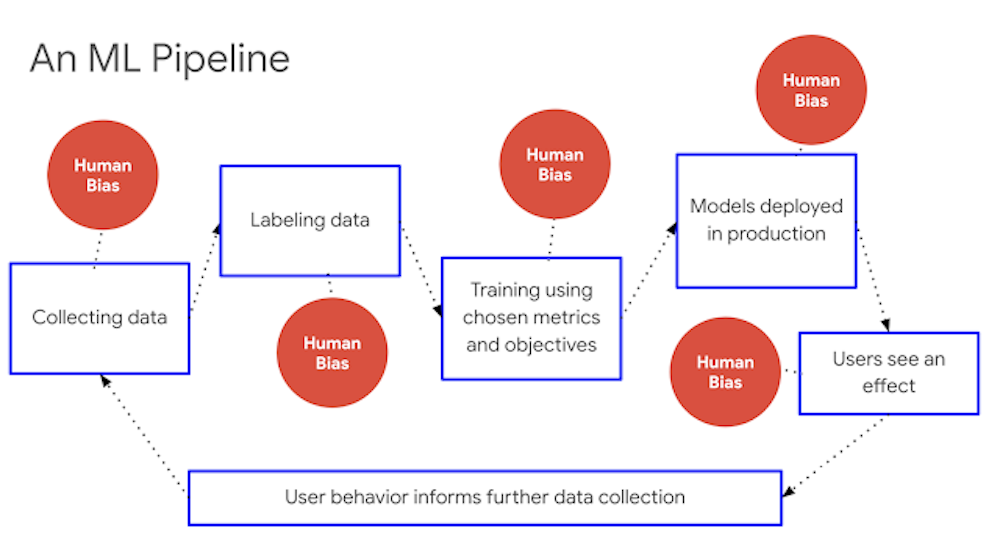
Empecemos analizando la recopilación de datos. Entre 1940 y 1990 compañías como Kodak y Polaroid solo usaron modelos blancos para calibrar sus productos. Treinta años después, seguimos teniendo los mismos sesgos raciales con la tecnología.
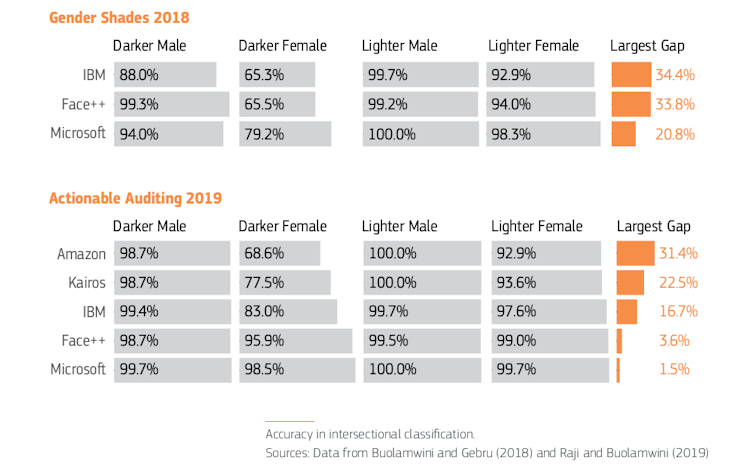
El estudio Gender Shades midió la precisión de la clasificación comercial de sistemas de Microsoft, IBM y Face ++ para descubrir que las mujeres de piel más oscura eran clasificadas erróneamente con mayor frecuencia que el resto. Los sistemas funcionaban mejor en rostros de hombres que de mujeres y en pieles claras que oscuras.
Una actualización del estudio en 2019 volvió a probar los tres sistemas comerciales previamente examinados y amplió la revisión para incluir Amazon Rekognition y Kairos. IBM, Face ++ y Microsoft habían mejorado su precisión. Sin embargo, las plataformas de Amazon y Kairos tenían unas brechas de precisión del 31% y 22,5%, respectivamente, entre hombres de piel más clara y mujeres de piel más oscura.
Amazon, en vez de tomar nota y tratar de corregir el problema, comenzó toda una campaña de desprestigio de la investigación y, más en concreto, de la figura de una de sus responsables, Joy Buolamwini.
Este es un ejemplo de sesgo interseccional, donde diferentes tipos de discriminación amplifican los efectos negativos para un individuo o grupo. La interseccionalidad describe formas cruzadas de opresión y desigualdad que surgen de ventajas y desventajas estructurales derivadas de la pertenencia a múltiples categorías sociales superpuestas como género, sexo, etnia, edad, nivel socioeconómico, orientación sexual, ubicación geográfica… Es decir, cada persona sufre opresión u ostenta privilegio en base a su pertenencia a múltiples categorías sociales.
El sesgo también puede introducirse durante la preparación de datos y la selección del modelo, lo que implica escoger atributos que el algoritmo debería considerar o ignorar, como los cosméticos faciales o la evolución de las caras de personas trans durante la transición.
Maquillaje y personas trans
Un estudio mostró que el maquillaje (usado principalmente por las mujeres en la mayoría de sociedades) reduce enormemente la precisión de los métodos de reconocimiento facial comerciales y académicos. La razón es que los cosméticos no se han establecido como un parámetro en las bases de datos faciales disponibles públicamente.
Una propuesta para desarrollar sistemas que sean robustos es mapear y correlacionar varias imágenes de la misma persona con y sin maquillaje. Estas soluciones también deben tener en cuenta las diferentes prácticas de maquillaje en las distintas culturas.
Otro de los desafíos emergentes son las caras de las personas trans, especialmente durante los períodos de transición. Por ejemplo, saltó a los medios el caso de una conductora trans de Uber que tenía que viajar todos los días dos horas para ir a una oficina local de la compañía dado que no funcionaba con ella la app que solicita periódicamente a conductores que envíen selfies para verificar su identidad antes de comenzar un turno.
La terapia hormonal redistribuye la grasa facial y cambia la forma y textura general del rostro. Dependiendo de la dirección de la transición (es decir, de hombre a mujer o de mujer a hombre), los cambios más significativos en la cara transformada afectan las arrugas y líneas, las estrías, el engrosamiento o adelgazamiento de la piel y las variaciones de textura. La terapia con hormonas, por ejemplo, hace que la cara sea más angular.
¿La solución es corregir los prejuicios asegurando que se incluyan muchas personas trans en los datos de entrenamiento de la IA? La idea, en un primer momento, puede sonar bien, pero recoger y almacenar datos de una comunidad que tiene motivos para sentirse incómoda con esta recopilación, no es la mejor práctica. En este caso, puede ser importante revisar los parámetros algorítmicos. Los métodos existentes indican que en estos casos, la región ocular (o periocular) se puede utilizar de forma más fiable en comparación con el uso de la región de rostro completo, ya que se ve menos afectada por el cambio que otras.
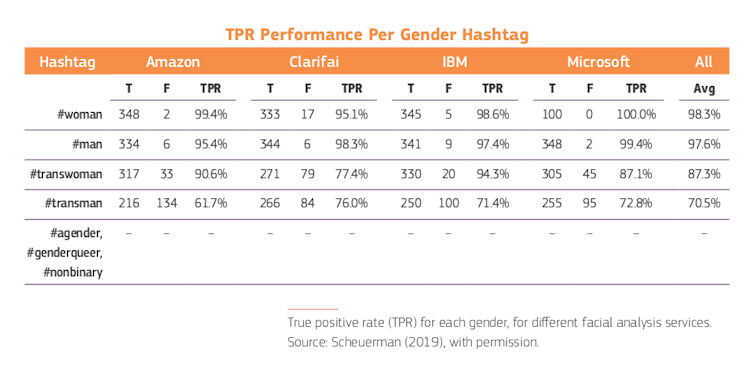
Otro estudio halló que cuatro servicios comerciales (Amazon Rekognition, Clarifai, IBM Watson Visual Recognition y Microsoft Azure) tuvieron un desempeño deficiente en personas trans y no pudieron clasificar géneros no binarios.
Usando el hashtag proporcionado por las personas en sus publicaciones de Instagram (#woman, #man, #transwoman, #transman, #agender, #genderqueer, #nonbinary), el equipo calculó la precisión de los resultados de clasificación de género en 2 450 imágenes. En promedio, los sistemas clasificaron a las mujeres cis (#women) con un 98,3% de precisión y a los hombres cis (#man) con un 97,6%. La precisión disminuyó para las personas trans, con un promedio de 87,3% para #transwoman y 70,5% para #transman. Aquellas personas que se identificaron como #agender, #genderqueer o #nonbinary fueron mal caracterizadas el 100% de las veces.
Hora de repensar la tecnología
Ante todas estas incógnitas éticas, compañías como IBM han cesado por completo el desarrollo de software de reconocimiento facial, mientras que Amazon y Microsoft han hecho un parón temporal en la venta de sus sistemas a la policía.
Visto lo sucedido con el despido por parte de Google de Timnit Gebru, una de sus líderes de ética (y precisamente otra de las impulsoras del estudio de Gender Shades), es peligroso dejar las llaves del gallinero al zorro.
Como bien dice Cathy O’Neil, otra activista por una IA ética: «No se puede confiar en que las empresas verifiquen su propio trabajo, especialmente cuando el resultado pueda entrar en conflicto con sus intereses financieros».
Para no perpetuar e incluso amplificar los patrones sociales de injusticia al codificar consciente o inconscientemente los prejuicios humanos, tenemos que pasar del «modo reactivo» (poniendo parches cuando se encuentran los problemas) al «modo proactivo», incorporando el análisis interseccional desde la misma concepción de los proyectos.
Para ello, desde la Comisión Europea se ha publicado un informe (Gendered Innovations 2) en el que hemos desarrollado quince estudios de caso y métodos para mostrar cómo ayudar a la investigación a desarrollar tecnologías más justas y responsables. Nuestro objetivo es concienciar a la ciudadanía, a las organizaciones y a la administración pública de este problema y así crear tecnologías que funcionen para toda la sociedad y no solo para las mayorías con poder.![]()
Este artículo fue publicado originalmente en The Conversation. Lea el original.
![]()